Analysis of unstructured text-based data using machine learning techniques: the case of pediatric emergency department records in Nicaragua
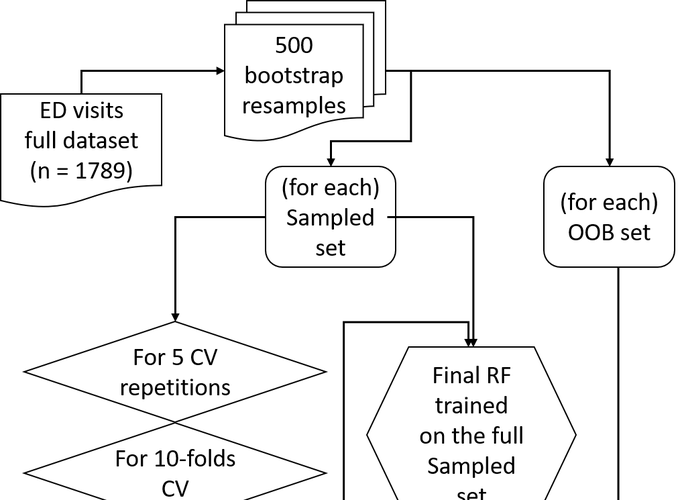 Training procedure
Training procedure
Analysis of unstructured text-based data using machine learning techniques: the case of pediatric emergency department records in Nicaragua
Abstract
Free text information is still widely used Emergency Department (ED) records. Machine Learning Techniques (MLT) are useful for analyzing narratives, but they have been used mostly for English-language datasets. Considering such a framework, it was tested the performance of an ML classification task of a Spanish-language ED visits database. ED visits collected in the EDs of nine hospitals in Nicaragua were analyzed. Spanish-language, free-text discharge diagnoses were considered in the analysis. Five-hundred Random Forests were trained on a set of bootstrap samples of the whole dataset (1789 ED visits) to perform the classification task. For each one, after having identified optimal parameter value, the final validated model was trained on the whole bootstrapped dataset and tested. The classification accuracies had a median of 0.783 (95% C.I. 0.779-0.796). MLTs seemed to be a promising opportunity for the exploitation of unstructured information reported in ED records in low- and middle-income Spanish-speaking countries.